System Design — Design A Rate Limiter

Note: I have read this great book System Design Interview — An insider’s guide by Alex Xu in depth. So most of my definitions and images will be referred from this book itself as they are highly interactive and give us a clear picture of what is happening.
A Rate Limiter limits the number of client requests allowed to be sent over a specified period. If the API request count exceeds the threshold defined by the rate limiter, all the excess calls are blocked.
For example, A user can only post up to 10 times in 1 minute, a user can only create up to 10 accounts per day from the same IP address, etc.
Before deep-diving into the implementation of a rate limiter, let’s look at its benefits:
- A rate limiter prevents DoS attacks, intentional or unintentional, by blocking the excess calls.
- Reduces cost where the system is using a 3rd-party API service and is charged on a per-call-basis.
- To reduce server load, a rate limiter is used to filter out excess requests caused by bots or users’ misbehaviour.
It mainly depends upon our application, tech stack, tech-team etc, where exactly we want the rate-limiter to be implemented. We have generally 3 places: Client-side, Server-side, or middleware.
The client is an unreliable place to enforce rate limiting because client requests can easily be forged by malicious actors.
Even better than placing it on the server side is to use a rate limiter middleware, which will throttle excess requests even to our server side. So, if you are using a microservice architecture and already using functionalities like authentication middleware, a similar basis you can implement rate limiter middleware alongside it.

There are plenty of algorithms for rate limiting: we will look at some of them including a Token bucket, Leaky bucket, Sliding window counter, etc.
Token Bucket Algorithm
Stripe (read here) uses a token bucket algorithm to throttle their API requests.
As per the Stripe tech blog:
We use the token bucket algorithm to do rate limiting. This algorithm has a centralized bucket host where you take tokens on each request, and slowly drip more tokens into the bucket. If the bucket is empty, reject the request. In our case, every Stripe user has a bucket, and every time they make a request we remove a token from that bucket. We implement our rate limiters using Redis.

The bucket has tokens with a pre-defined capacity. When a request comes in it takes a token from the bucket and is processed further. If there is no token to be picked, the request is dropped and the user will have to retry.
Example use-case:
- We have our rate-limiting rules set to 3 requests per user per minute.
- User1 makes the request at 00 time interval, currently the bucket is full with 3 tokens so request will be processed. Tokens will be updated in the bucket to 2 now.
- User1 makes a 2nd request at 10th sec, bucket has 2 tokens so again the request will be processed further. Tokens will be updated in the bucket to 1 now.
- User1 makes a 3rd request at say 30th sec, bucket has 1 token so again the request will be processed further. Now the bucket is empty till the whole 1 minute completes.
- User1 makes a 4th request at say 55th sec, the bucket has 0 tokens so the request is throttled and the user is returned with a 429 status code — too many requests and asked to retry it later in some time. The HTTP 429 Too Many Requests response status code indicates the user has sent too many requests in a given amount of time.
- At the completion of that 1 minute, the token count is refreshed at a fixed rate and the bucket is again full with 3 tokens and requests can be processed again for that particular user.
In simple words:
In the Token Bucket algorithm, we process a token from the bucket for every request. New tokens are added to the bucket with rate r. The bucket can hold a maximum of b tokens. If a request comes and the bucket is full it is discarded.
The token bucket algorithm takes two parameters:
- Bucket size: the maximum number of tokens allowed in the bucket
- Refill rate: number of tokens put into the bucket every second

Algorithm design in Golang:
package main
import (
"fmt"
"math"
"time"
)
const (
MAX_BUCKET_SIZE float64 = 3
REFILL_RATE int = 1
)
type TokenBucket struct {
currentBucketSize float64
lastRefillTimestamp int
}
func (tb *TokenBucket) allowRequest(tokens float64) bool {
tb.refill() //refill of bucket happening at constant REFILL_RATE
if tb.currentBucketSize >= tokens {
tb.currentBucketSize -= tokens
return true
}
return false
}
func getCurrentTimeInNanoseconds() int {
return time.Now().Nanosecond()
}
func (tb *TokenBucket) refill() {
nowTime := getCurrentTimeInNanoseconds()
tokensToAdd := (nowTime - tb.lastRefillTimestamp) * REFILL_RATE / 1e9
tb.currentBucketSize = math.Min(tb.currentBucketSize+float64(tokensToAdd), MAX_BUCKET_SIZE)
tb.lastRefillTimestamp = nowTime
}
func main() {
obj := TokenBucket{
currentBucketSize: 3,
lastRefillTimestamp: 0,
}
fmt.Printf("Request processed: %v\n", obj.allowRequest(1)) //true
fmt.Printf("Request processed: %v\n", obj.allowRequest(1)) //true
fmt.Printf("Request processed: %v\n", obj.allowRequest(1)) //true
fmt.Printf("Request processed: %v\n", obj.allowRequest(1)) //false, request dropped
}Leaky Bucket Algorithm
Leaky Bucket is a simple and intuitive way to implement rate limiting using a queue. It is a simple first-in, first-out queue (FIFO). Incoming requests are appended to the queue and if there is no room for new requests they are discarded (leaked).

- When a request arrives, the system checks if the queue is full. If it is not full, the request is added to the queue.
- Otherwise, the request is dropped.
- Requests are pulled from the queue and processed at regular intervals.
How the algorithm works:

The leaking bucket algorithm takes the following two parameters:
- Bucket size: it is equal to the queue size. The queue holds the requests to be processed at a fixed rate.
- Outflow rate: it defines how many requests can be processed at a fixed rate, usually in seconds.
This algorithm’s advantage is that it smooths out bursts of requests and processes them at an approximately average rate.
Sliding Window Algorithm
- The algorithm keeps track of request timestamps. Timestamp data is usually kept in cache, such as sorted sets of Redis.
- When a new request comes in, remove all the outdated timestamps. Outdated timestamps are defined as those older than the start of the current time window.
- Add timestamp of the new request to the log.
- If the log size is the same or lower than the allowed count, a request is accepted. Otherwise, it is rejected.
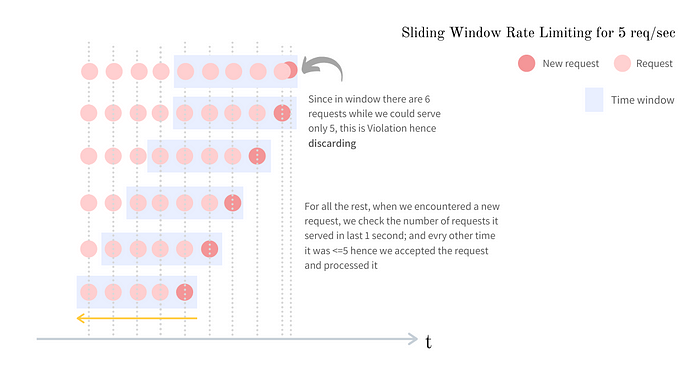
In the below example, rate limiter allows us 2 requests per minute. Anything beyond this within the window will be dropped.
Note: For ease of understanding, we have used a hh:mm:ss format, but in redis we will be pushing the UNIX timestamps.

- The log is empty when a new request arrives at 1:00:01. Thus, the request is allowed.
- A new request arrives at 1:00:30, the timestamp 1:00:30 is inserted into the log. After the insertion, the log size is 2, not larger than the allowed count. Thus, the request is allowed.
- A new request arrives at 1:00:50, and the timestamp is inserted into the log. After the insertion, the log size is 3, larger than the allowed size 2. Therefore, this request is rejected even though the timestamp remains in the log.
- A new request arrives at 1:01:40. Requests in the range [1:00:40,1:01:40) are within the latest time frame, but requests sent before 1:00:40 are outdated. Two outdated timestamps, 1:00:01 and 1:00:30, are removed from the log. After the remove operation, the log size becomes 2; therefore, the request is accepted.
To read more about this, read this amazing article by Arpit Bhayani
Detailed Design of a Rate Limiter:
Here we are using the below components:
- Config and data store to store the rate limiter rules
- Workers frequently pull rules from the disk and store them in the cache
- Rate Limiter Middleware fetches rules from the cache. It also fetches data such as timestamps, counter etc. from Redis. Then it does the computation when a request comes and decides whether to process the request or rate limit it.
- In case of rate limiting the request — here we have 2 options
- Option 1: To drop the request and send a status code of 429: too many requests back to the client.
- Option 2: Push it to a Message queue to process this request later.

Now we might need to scale our above system for a distributed environment to support multiple servers and concurrent threads. Here 2 challenges might arise:
Race condition
As discussed above:
Read the counter value from Redis and check if ( counter + 1 ) exceeds the threshold. If not, increment the counter value by 1 in Redis.

Assume the counter value in Redis is 3 (as shown in the image above). If two requests concurrently read the counter value before either of them writes the value back, each will increment the counter by one and write it back without checking the other thread. Both requests (threads) believe they have the correct counter value 4. However, the correct counter value should be 5.
Locks can be useful here, but that might impact the performance. So we can use Redis Lua Scripts.
- This may result in better performance.
- Also, all steps within a script are executed in an atomic way. No other Redis command can run while a script is executing.
Synchronization
Synchronization is another important factor to consider in a distributed environment. To support millions of users, one rate limiter server might not be enough to handle the traffic. When multiple rate limiter servers are used, synchronization is required.
One possible solution is to use sticky sessions that allow a client to send traffic to the same rate limiter. This solution is not advisable because it is neither scalable nor flexible. A better approach is to use centralized data stores like Redis.
After things are in place, we can also monitor our rate limiter for metrics like performance, rules, algorithm effectiveness, etc. For example, if rate-limiting rules are too strict, many valid requests are dropped. In this case, we want to relax the rules a little bit. In another example, we notice our rate limiter becomes ineffective when there is a sudden increase in traffic like flash sales. In this scenario, we may replace the algorithm to support burst traffic. The token bucket is a good fit here.
